
Why "ML in Health Science"
DOI:
https://doi.org/10.62487/e4ccm968Keywords:
Web3 Journal: ML in Health Science , Logo, Symbolism , Human-centered AIAbstract
This is the first editorial of the journal, discussing the balance between humans and AI in healthcare and emphasizing the need for a human-centric approach in AI and ML applications.
![]()
AI Snake
Explore ML as a Game
x
This model is designed to target specific objectives during training.
x
This model does not focus on specific objectives and allows for more exploration.
x
This model encourages exploration by incorporating curiosity-driven learning.
x
Adjust the proportion between generated data and experience data used during training.
x
Adjust the speed at which the snake moves. Lower values mean higher speed.
x
Fine-tune the model using existing training data to improve its performance incrementally.
x
Train the model from scratch using a new set of data for a completely fresh start.
x
Number of times the model will cycle through the training data.
x
Number of training examples utilized in one iteration.
x
How much to change the model in response to the estimated error each time the model weights are updated.
x
Rate at which the learning rate decreases after each epoch.
x
Penalty term added to the loss function to encourage smaller weights and reduce overfitting.
x
Alpha parameter for the Leaky ReLU activation function, controlling the slope of the activation for negative inputs.
x
Fraction of input units to drop to prevent overfitting during training.
x
Number of epochs with no improvement after which training will be stopped.
x
Minimum change in the monitored quantity to qualify as an improvement.
x
Threshold to clip gradient norms to prevent exploding gradients during training.
x
Coefficient for the entropy term in the loss function to encourage exploration.
x
Level of noise added to the state inputs to improve robustness.
x
Reward value for the snake when it eats food.
x
Penalty value for the snake when it collides with itself.
x
Penalty value for the snake for each move it makes (encourages faster completion).
x
Penalty value for the snake if it fails to make progress towards the food.
x
Reward value for the snake based on its proximity to the food.
x
Size of the replay buffer that stores experiences for training.
x
Exponent for prioritizing experiences in the replay buffer.
x
Small value added to priorities to ensure all experiences have a non-zero probability of being selected.
x
Probability of selecting a random action instead of the best action during training.
x
Rate at which the exploration epsilon decreases after each episode.
x
Minimum value for the exploration epsilon to ensure some exploration is always present.
This tool is designed to help you understand the principles of building Machine Learning models through gameplay. The Snake is guided by a reinforcement learning process using feedforward neural network predictions, with training data generated from auto gameplay. Experiment with parameters and observe the performance.
Ask the Transformer
about the principles of model building and the influence of settings on performance.
If you would like to see how the ML works: right-click, select "Inspect," open the Console of your browser, and enjoy the heartbeat of the machine.
If you want to deploy your own ML app, visit ML in Health Science: Playground
If you would like to see how the ML works: right-click, select "Inspect," open the Console of your browser, and enjoy the heartbeat of the machine.
If you want to deploy your own ML app, visit ML in Health Science: Playground
Editorial
"...whatever can happen of all things have already happened, been done..."
Friedrich Nietzsche "Also sprach Zarathustra: Vom Gesicht und Raetsel"
Artificial Intelligence (AI) is at an early stage of its own evolution. It is controlled by human beings. It is fascinating to see how this technology can predict the future. It makes our life easier. It reduces the time needed to solve various statistical, mathematical, linguistic, and recently, healthcare problems. However, what does AI really mean for humanity?

This ancient symbol of "conducive to wellbeing"1 was transformed 80 years ago into a symbol of human extinction. Enormous effort and millions of human lives were sacrificed to stop the advancement of this once revered emblem.
Could AI have the same historical evolution as the ancient symbol above? Lets look at the core of Python and machine learning. Each predictive model is based on simple regression analysis with a classic confusion matrix or 2x2 table: true positive, true negative, false positive, false negative:
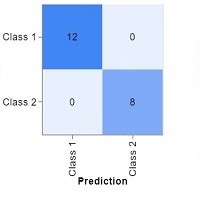
The extremely rational logic, or the "Zen of Python", is the code that drives this technology2. It possesses enormous memory power and makes decisions based on statistical models and big data. However, the abstract human way of thinking and individual approach have no place here, because regression requires data, and data signifies "no individual":

The IT developers lack experience with healthcare standards and are unfamiliar with the natural life processes from birth to death.
They do not comprehend the true essence of life. Healthcare professionals with clinical experience have a critical view of these natural processes. However, they often overestimate the capabilities of AI technologies, perhaps due to a lack of understanding that ML is essentially multi-layered statistical analysis.
As long as machines are controlled by humans, and humans maintain a critical perspective on what machines are, we see a collaboration between humans and machines. However, the current trend is towards controlled by AI machine-to-machine communication, initially described in 1968 by the Greek-American inventor and businessman Theodore Paraskevakos3 as the simple Internet of Things (IoT). This trend can represent a dominance of the "Zen of Python" over humanity.
Nowadays, people use AI to write daily content such as birthday congratulations or reminders, and often receive responses generated by another AI. A particularly concerning scenario, which is becoming a reality, involves the use of ML algorithms in healthcare to predict outcomes. This data is then used by GPT systems to make final decisions about a patient's diagnosis and treatment.
The mission of the "ML in Health Science" initiative is to maintain a balance between humans and AI, preventing the transformation of the confusion matrix into the ancient symbol that nearly cost humanity its future. We aim to enhance research in human-centric ML and AI by applying the critical insights of a community that possesses both clinical and ML experience:

Enjoy reading our publications. We welcome your feedback and invite you to become part of a community dedicated to promoting human wellbeing.
Conflict of Interest: YR states that no conflict of interest exists.
References
1 Britannica, The Editors of Encyclopaedia. "swastika." link. Accessed January 12, 2024.
2 Peters T. PEP 20 - The Zen of Python. link.
3 Goeller T, Wenninger M, Schmidt J. Towards Cost-Effective Utility Business Models. Selecting a Communication Architecture for the Rollout of New Smart Energy Services. link. Accessed January 12, 2024.
Downloads
Published
01.01.2024
Issue
Section
Editorial
License
Copyright (c) 2024 Dr. Yury Rusinovich (Author)

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
How to Cite
Rusinovich, Y. (2024). Why "ML in Health Science". Web3 Journal: ML in Health Science, 1(1). https://doi.org/10.62487/e4ccm968





Add a Comment:
Comments:
Article views: 0